
How to solve this level:
easily find this code:
<div id=”content”> There is nothing on this page <!– No more information leaks!! Not even Google will find it this time… –> </div>
just need to find robots.txt file in URL. Quite easy. but this is the first time I know robots.txt file. So I go deeper to see more about it.
The Robots.txt file is a set of instructions for robots. Included in the source files of most websites, the robots.txt file is primarily used to manage benign bot activity in the form of web crawlers, as malicious bots are less likely to follow these instructions.
Think of the robots.txt file as a “code of conduct” sign posted on the wall of a gym, bar or community centre: the sign itself does not have the power to enforce the rules listed, but “good” customers will follow the rules, while “bad” customers may break the rules and be evicted.
Bots are automated computer programmes that interact with websites and applications. There are both benign and malicious bots, and one type of benign bot is called a web crawler. These robots “crawl” web pages and index content so that it can be displayed in search engine results. robots.txt files help manage the activities of these web crawlers so that they do not overload the web server hosting the site or index pages that are not intended to be public.
for example:
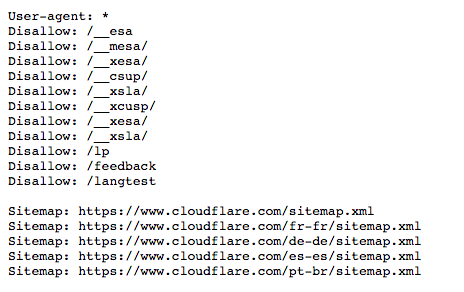
While I was looking, I also found a little surprise from google:
