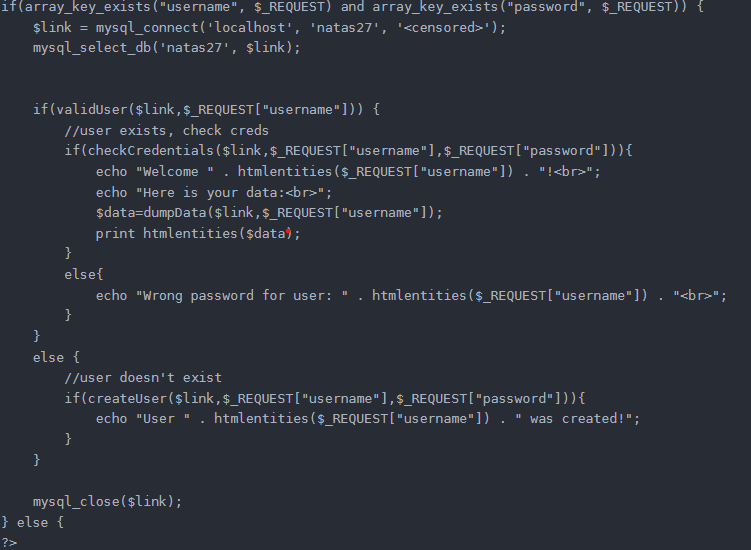
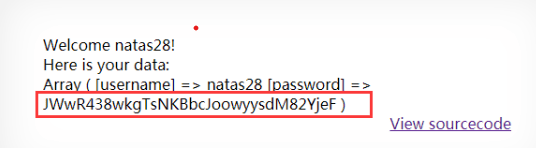
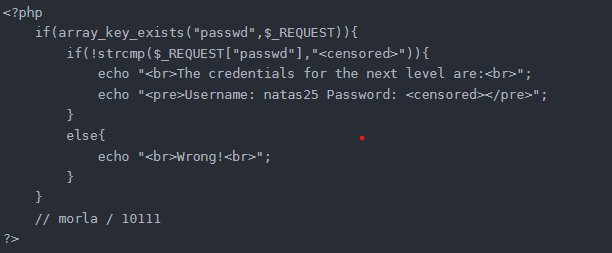
TL;ND :
This blog includes the usage of these features:
- Use Struct
- Use option<>, Some()
- Use if statement
- Use fn to create a function
- Use For loop
Details:
Well, practice is the best learning. Start my task in a simple coding task (in fact, it is one of my homework questions), here is the question:
Across the broad range of the multiverse, there are an infinite number of universes! These universes however follow a pattern, allowing us to write code in order to output the details of a universe, given its id.
You have been given a crate, multiverse, which does not compile!
Your task is to modify the given structure, get_universe_details function and the noted areas of the main function, inside multiverse/src/main.rs, such that it loops through id’s of 1-15, and prints out the universe details of the universe with that ID.
The universe lookup follows some basic rules:
- If the universe id is divisible by 3 – then that universe is the star wars universe, where the rebels won and the population is the max number that a u32 can fit!
- If the universe id is divisible by 5 – then it is the miraculous ladybug universe, where the villian Hawk Moth won, leaving the universe with a population of 22.
- Finally, if the universe id is divisible by both 5 and 3 – then it is the Stardew Valley universe, where the evil Jojo Corp won, leaving a population of only one!
Here is the anwser (of course in Rust language):
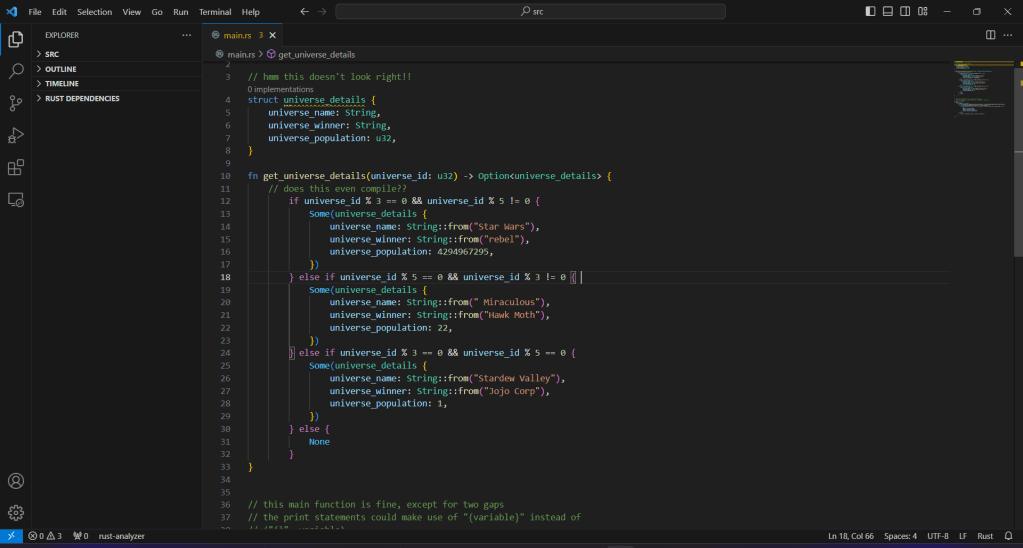
use std::string;
// hmm this doesn't look right!!(forget this)
struct universe_details {
universe_name: String,
universe_winner: String,
universe_population: u32,
}
fn get_universe_details(universe_id: u32) -> Option<universe_details> {
// does this even compile??()
if universe_id % 3 == 0 && universe_id % 5 != 0 {
Some(universe_details {
universe_name: String::from("Star Wars"),
universe_winner: String::from("rebel"),
universe_population: 4294967295,
})
} else if universe_id % 5 == 0 && universe_id % 3 != 0 {
Some(universe_details {
universe_name: String::from(" Miraculous"),
universe_winner: String::from("Hawk Moth"),
universe_population: 22,
})
} else if universe_id % 3 == 0 && universe_id % 5 == 0 {
Some(universe_details {
universe_name: String::from("Stardew Valley"),
universe_winner: String::from("Jojo Corp"),
universe_population: 1,
})
} else {
None
}
}
// this main function is fine, except for two gaps
// the print statements could make use of "{variable}" instead of
// ("{}", variable)
fn main() {
for id in 1..=15 {
let universe_details = get_universe_details(id);
if let Some(details) = universe_details {
println!("Universe with id {} is called {}, won by {} and has a population of {}",
id,
details.universe_name,
details.universe_winner,
details.universe_population
);
} else {
println!("Universe with id {id} is unknown");
}
}
}The use of struct in Rust language is quite like what in Python and C language, we build our data style and it can be used as a normal data type. It’s just like a big bag or a kind of Excel(???). We put whatever we want into it and make it easy for us to use. Remember, every feature in Struct should end with a “,” not “;”.
The If statement is also similar to what is in Python and C. Just allow us to choose among different selections. Only one thing needs our attention —— in Rust, every IF needs an ELSE or ELSE IF statement, except IF LET. IF LET is a “crap crap”(I use this world to discribe a feature are used only for Rust language) feature, it is a simplifyed MATCH statement, always be used as:
if let Some(x) = 123{
// Do something
}else {
// Do something else
}It can easily tests if a pattern matches and deconstructs a value in case of a match. Always use with Some() <- another “crap” function, means:”there are something on this variable, or None“. Option<…> is also “crap”: Type Option represents an optional value: every Option is either Some and contains a value, or None, and does not. Very useful in Rust code.
FN <- use to make a function, like def in Python. Remember, if a function is declear like this:
fn some_function(some_type) -> option<some_type>{
// Do something
}
Its return type should be somthing like Some(…) and None. Function in Rust will take its last behavior as return value automatically, or we can use RETURN to change that value.
For loop is the same with Python, but I notice one thing:
- For i in 1..15 means 1 -> 14
- For i in 1 ..= 15 means 1 -> 15
That’s all I learnt today, it is really a shit job to learn a new language. However, I will keep going —— For honor and glory.